Reducing the Attack Surface through Secure Configuration Management
By Patrick Goldsack
The role of Configured Things Ltd. within the Synergia project is to produce a multi-tenanted platform for configuring and managing IoT devices, the data that flows from devices, and analytics that need to be applied at both the edge and the backend. This includes the ability to securely share data and control, and to be able to delegate the management activities in a secure way.
The basic architecture is illustrated in the diagram:
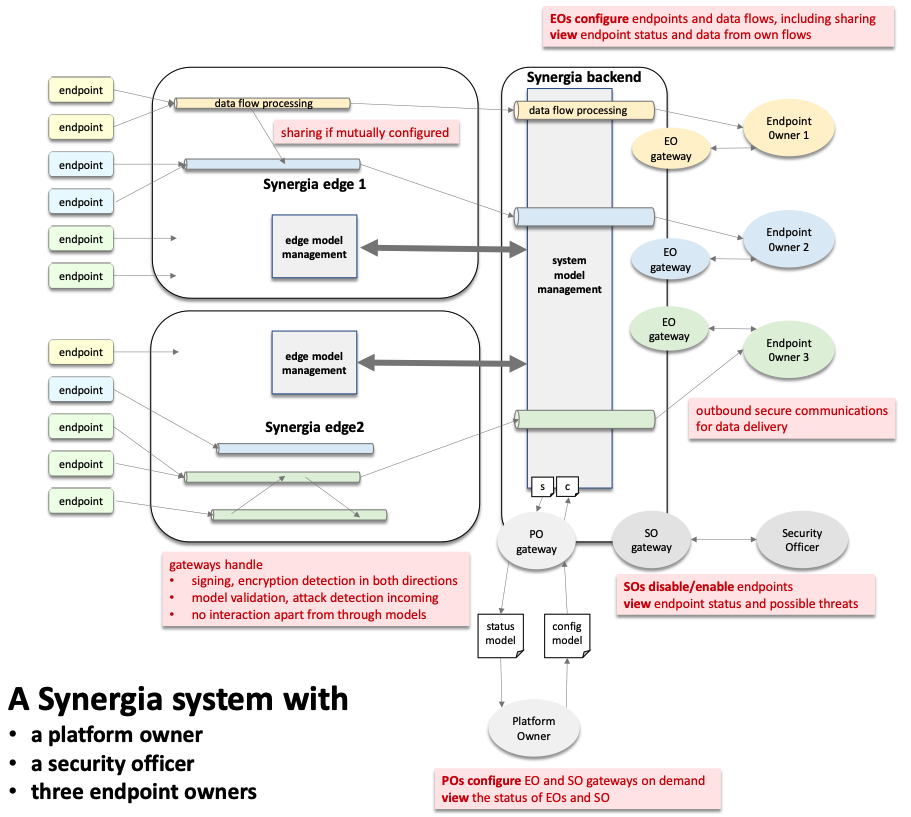
The system here consists of three roles: the platform owner who can configure new endpoint owners to join the platform, endpoint owners who own the endpoints that connect to the edge and supply data to the data flows, and for good measure a security officer who can force-detach any endpoint that has been identifies as a threat.
This is best illustrated by the deployment of the Synergia platform into Future Space – a space for SMEs and start-ups with many leased offices and laboratories, as well as communal shared spaces such as meeting rooms and open areas. In this deployment Synergia is providing the distributed, low-energy IoT platform consisting of a back-end, connected to multiple edge devices over standard networking technologies, and those in turn securely connected to a myriad of extremely low-power battery-driven wireless IoT devices. These IoT devices, mostly sensors, are installed in a variety of physical locations.
The platform provides to each of the tenants of the building – the endpoint owners – the ability to add new IoT devices and collect and analyse data in a way that is private to them, or shared with their permission with the other tenants. Future Space are considered here to be the Platform Owner and probably the Security Officer.
The configuration of this space is dynamic and complex, and so we have been developing a platform to enable the secure configuration and management of the system, and the stream of changes to that configuration. This is done in a way that is to be able to handle multiple overlapping and conflicting changes that need to be automatically authorised, validated processed and reconciled.
The approach taken has properties which make it particularly suitable for use in complex, distributed environments such as connected places and other IoT deployments that are the target domains for Synergia.
- It uses a declarative approach to describing configuration requirements which can be submitted and retracted as required
- It provides modelling that can be specialised and scoped to each tenant
- It considers configuration state to be the list of currently authorised configuration requirements (effectively change requests) relative to the notional “safe baseline” state
- It takes a zero-trust approach to the origin and transport of these change requests
In the architecture diagram, this approach is illustrated as every interaction in both directions (configuration and status) is through the exchange of signed, encrypted (if required as, for example, the configuration contains a secret), and otherwise validated declarative configuration requirements.
Given that in a connected place, configuration change is not simply an infrequent system administration task, it is in effect the currency and interface between systems that need to cooperate. This observation is the driving force behind the consideration of configuration change as the primary requirement. However, whilst the ability of a system to change or be changed by multiple tenants is a key part of its value, it is also a major security problem of the widened attack surface of the system. Misconfiguration, whether unintentional, malicious, or simply because a previously valid change has been invalidated by a change in policy, is the root cause of most security breaches.
The traditional mitigation to this has been to enforce strong change control processes, rigorous testing, and limiting the pool of trusted actors that can initiate change. However, in a complex multi-party ecosystem such as a Connected Place, where systems are inherently decentralised, such approaches are limited in their effectiveness. Such processes are not designed for cross-tenant change management.
The emergence of DevOps has brought with it an increase in the adoption of declarative approaches for service deployment and configuration, which abstract the complexity of how to implement a change away from the specification of the required state. In much the same way that a Satnav only needs to be given the destination and can work out for itself how to get there regardless of the current location, declarative systems accept a definition of the required state (the destination) and work out the set of changes needed to bring the system into alignment (the route).
When implemented correctly, declarative systems are robust (as they hide the complexities of state management), are simpler to interact with than a transactional API (because they allow the user to focus on the required outcome) and provide direct tractability to who requested / authorised the current configuration of the system.
Such declarative systems have now become predominant for infrastructure provisioning (AWS Cloud Formations, Azure Resource manager, Terraform, etc) and for containerised applications (k8s/helm, etc).
However, the current generation of systems all share a number of limitations in this context:
- They are generally focused on, and limited to, a linear sequence of states where each change is presented to the system as a complete new version of all or some part of the system. In the code analogy underpinning DevOps this is like moving from release to release along the main branch. This creates problems when, for example, it becomes necessary to isolate and remove a single faulty or malicious change. Our approach is more akin to simultaneously managing and releasing from multiple branches.
- They are ‘release’, rather than ‘change’, focused, and work with relatively static configurations. Where there is dynamic behaviour (e.g., some form of auto scaling) they describe the configuration of that rather than act as the controller.
- They assume non-overlapping trust domains; while it is best practice to divide the system into stacks for different layers or service areas, each of these then effectively has an owner or owners with full control of that part of the system.
- There is limited consideration of domains driving sometimes conflicting changes, requiring reconciliation based on policy.
- There is limited granularity for defining the scope of what can be changed within an area; modules will typically have a fixed set of parameters that can be supplied, values that can be inspected, and may provide default values and some type checking. Within a trust domain this may provide a reasonable level of protection and flexibility, but we need to be able to add finer-grained constraints without having to define a complex authorisation model.
The platform allows us to build declarative systems that overcome these limitations, based on the following principles:
- The inputs to the platform define the desired outcome of a change request. This can of course be a full description of some part of the system, but it can also be of some subset.
- Change requests come from several different sources, be it people or other systems, and must be authenticated appropriately.
- The language used to express a change request should as far as possible limit what can be requested; It’s much harder to make the ‘insecure’ changes if you can’t even describe it. This is an essential aspect to reducing the attack surface and is the analogue of Newspeak in the book 1984, where Orwell writes:
“Don’t you see that the whole aim of Newspeak is to narrow the range of thought? In the end we shall make thoughtcrime literally impossible, because there will be no words in which to express it.”
- Change requests may overlap in scope and may be in conflict. The system must resolve these automatically in a deterministic way.
- Change requests are idempotent – that means that resubmission of a change has no impact beyond that of the original change. This is essential to building robust disaggregated systems, making system recovery considerably easier.
- It needs to be as easy to remove a change request as it was to make it in the first place, whether that’s in response to a change in intent or a change in permission.
- Permission to make a change may require multiple parties to authorise it. Maybe someone from each of two cooperating tenants, or perhaps dual sign-off from one organisation to help mitigate against an insider attack. These policies around permission need to be rich enough to represent required authorisation structures, but equally simple enough to be able to reason about the security and to operate them in practice.
- Changes that span across multiple tenants must be independently agreed by all the parties, and any party to a change may subsequently withdraw permission, and the system should reconfigure itself accordingly. An example might be data sharing between two tenants of a connected place, there must be a matching offer of data and request for data for that sharing to be enacted. Either party could withdraw from the agreement, and at that point the underlying system should immediately remove the capability.
- Zero trust should apply to changes in the same way that it applies to networks; the trust should be associated with the change itself, and not the transport or origin.
If we look briefly at how the platform meets these principles:
Our inputs are the desired outcome of a change request.
This might seem like a small point, but it underlies much of how the platform works, and is a different paradigm from declarative systems which take new complete models or modules. For a start it means the way in which we derive the new required state is itself stateless. Change requests from different sources can arrive or be removed in any order and at any time, and we re-evaluate the new desired state.
It needs to be as easy to remove a change request as it was to make it in the first place.
This is an important property in a dynamic system, with multiple sources of change. As described above, the only state in our system is the current set of change requests. This has a specific impact when considering the impact of removing a change request – the result of which is always a new calculated state (which considers all subsequent change requests) and avoids any need for complex “undo” handling.
Change requests may overlap in scope and may be in conflict. The system must resolve these automatically in a deterministic and idempotent way.
Like other declarative systems our input is serialised data, in our case an extended form of JSON. Each interface to our platform accepts change requests and a priority, the base level for which may be defined by the specific interface. Whilst this is an extremely simple policy model for resolving conflicts, it appears to be adequate for current needs and more sophisticated approaches are being considered.
Change requests come from several different sources, which might be people or other systems.
Rather than have a single interface used by all sources, with a common authentication and role-based access control model we provide a separate interface for each source. Our API operations are simply “Make this change request” and “Remove this change request”. Each interface has its own constraints on ‘if’ and ‘how’ change requests are passed into the system. Interfaces are added and removed from the system dynamically according to need, which helps keep the attack surface small.
The language used to express a change request should as far as possible limit what can be requested
It is also possible to apply a range of rich schema constraints on each interface, to limit the scope of change requests it can process. Further, each interface is configured to limit the scope of the change requests it accepts by specifying the root object against which they will be applied. In this way it is not possible for an interface accepting change requests for sensors to accidentally expose the capability to modify network settings.
The remaining principles relate to our security model:
Authentication and non-repudiation: Each change request can include one or more cryptographic signatures, which both verify the author(s) of the change request and the integrity of its content. For a change to be accepted the set of signatures must match the rules for that interface, which can for example be “Any of Alice, Bob or Charlie”, “At least two of …”, “Any signature from this Organisation”, etc.
Note that the authentication is against each change request. It does not otherwise depend on the origin, session, or transport used to bring the request to the system, which meets our Zero Trust principle.
Authentication is performed by each interface against its own specific policy. Change requests which do not meet the policy are rejected. A change in policy always results in the re-authentication of all the change requests submitted via that interface (remember change requests are our only state), so any change in policy always takes immediate effect, and results in a new desired state that conforms to the policy (i.e., is only derived from authenticated change requests). This works well alongside certificate revocation, for example, and provides all the mechanisms for seamless frequent roll-over of keys. This can allow for the use of short-lived certificates.
Authorisation: Processing a change request is a merge of two data structures, the change request itself and the result of merging any higher priority change requests. Such an operation can create new values or update existing values.
In a comparable system with a REST API there would be operations for each object type with a corresponding RBAC rule to be configured to describe the permitted operations, the scope of which is a predetermined trade-off between granularity of control and complexity of rules.
In our platform this is replaced by constraints which can be placed at any point in the data structure to define under which conditions that part of the structure can be updated, extended, read, or referenced during the merge. The authorisation for these constraints is based on the signatures in the change request. Note that because it is embedded in the data structure the authorisation policy is itself part of the desired state of the system. So, for example a higher priority (processed first) change request can add or modify authorisation policy to some part of the system that is then enforced against lower priority change requests. As any change in the set of change requests results in a re-calculation of the desired state, any change in the authorisation policy is always applied immediately and the effect of any now-unauthorised changes are nullified.
The above probably paints a picture of some form of centralised policy / resolution engine, but what we implement is a mesh of such systems which exchange models with each other. And how do we describe and control what the system looks like? That too is just another form of configuration, so we use the same language and tooling to deploy and manage our system. In QA speak, we are customer zero of our product.
In Synergia we recently demonstrated this approach through three types of role, described n the diagram and each of which acts independently, yet collectively to control the overall state of the system: a Platform Operator who configures the IoT radio network and adds other roles to the system; one or more Endpoint Owners who configure devices and their associated data flows; and a Security Officer who can selectively disable devices that are perceived to have become a threat to the system. Each of the roles is an organisation who may have members with specific tasks and permissions. We enable each organisation to specify “who may change what” from that, and indeed other, organisations.
You can see the video here on our YouTube channel: https://youtu.be/yHa0g9LQsrQ